

It can be argued that the most important decisions in life are some variant of an exploitation-exploration problem. Shall I stick with my current job or look for a new one? Shall I stay with my partner or seek a new love? Shall I continue reading the book or watch the movie instead? In all of those cases, the question is always whether I should “exploit” the thing I have or whether I should “explore” new things. If you want to learn how to tackle this most basic trade-off read on…
At the core this can be stated as the problem a gambler has who wants to play a one-armed bandit: if there are several machines with different winning probabilities (a so-called multi-armed bandit problem) the question the gambler faces is: which machine to play? He could “exploit” one machine or “explore” different machines. So what is the best strategy given a limited amount of time… and money?
There are two extreme cases: no exploration, i.e. playing only one randomly chosen bandit, or no exploitation, i.e. playing all bandits randomly – so obviously we need some middle ground between those two extremes. We have to start with one randomly chosen bandit, try different ones after that and compare the results. So in the simplest case, the first variable  is the probability rate with which to switch to a random bandit – or to stick with the best bandit found so far.
is the probability rate with which to switch to a random bandit – or to stick with the best bandit found so far.
Let us create an example with  bandits, which return
bandits, which return  units on average, except the second one which returns
units on average, except the second one which returns  units. So the best strategy would obviously be to choose the second bandit right away and stick with it, but of course, we don’t know the average returns of each bandit so this won’t work. Instead, we need another vector
units. So the best strategy would obviously be to choose the second bandit right away and stick with it, but of course, we don’t know the average returns of each bandit so this won’t work. Instead, we need another vector  which tallies the results of each bandit so far. This vector has to be updated after each game, so we need an update function which gets as arguments the current bandit and the return of the game.
which tallies the results of each bandit so far. This vector has to be updated after each game, so we need an update function which gets as arguments the current bandit and the return of the game.
The intelligence of the strategy lies in this update function, so how should we go about it? The big idea behind this strategy is called Bellman equation and in its simplest form it works as follows: the adjustment of the former result vector is the difference between the former result and the current result weighted by some discount factor, in this case, the inverse of the number of games played on the respective machine. This learning strategy is called Q-learning and is a so-called reinforcement learning technique.
Have a look at the following example implementation:
set.seed(3141) # for reproducibility
# Q-learning update function
update <- function(i, r) {
Q[i] <<- Q[i] + 1/(k[i]+1) * (r-Q[i]) # Q-learning function
k[i] <<- k[i] + 1 # one more game played on i'th bandit
}
# simulate game on one-armed bandit i
ret <- function(i) {
round(rnorm(1, mean = rets[i]))
}
# chose which bandit to play
which.bandit <- function() {
p <- runif(1)
ifelse(p >= epsilon, which.max(Q), sample(1:n, 1))
}
epsilon <- 0.1 # switch in epsilon percent of cases
rets <- c(4, 5, 4, 4, 4) # average returns of bandits
n <- length(rets)
Q <- rep(0, n) # initialize return vector
k <- rep(0, n) # initialize vector for games played on each bandit
N <- 1000 # no. of runs
R <- 0 # sum of returns
for (j in 1:N) {
i <- which.bandit() # chose bandit
r <- ret(i) # simulate bandit
R <- R + r # add return of bandit to overall sum of returns
update(i, r) # calling Q-learning update function
}
which.max(Q) # which bandit has the highest return?
## [1] 2
Q
## [1] 4.000000 5.040481 4.090909 4.214286 3.611111
k
## [1] 32 914 22 14 18
N * max(rets) # theoretical max. return
## [1] 5000
R
## [1] 4949
R / (N * max(rets)) # percent reached of theoretical max
## [1] 0.9898
So, obviously, the algorithm found a nearly perfect strategy all on its own!

Now, this is the simplest possible application of reinforcement learning. Let us now implement a more sophisticated example: a robot navigating a maze. Whereas the difficulty in the first example was that the feedback was blurred (because the return of each one-armed bandit is only an average return) here we only get definitive feedback after several steps (when the robot reaches its goal). Because this situation is more complicated we need more memory to store the intermediate results. In our multi-armed bandit example, the memory was a vector, here we will need a matrix.
The robot will try to reach the goal in the following maze (i.e. to get out of the maze to reach F which can be done via B or E) and find the best strategy for each room it is placed in:
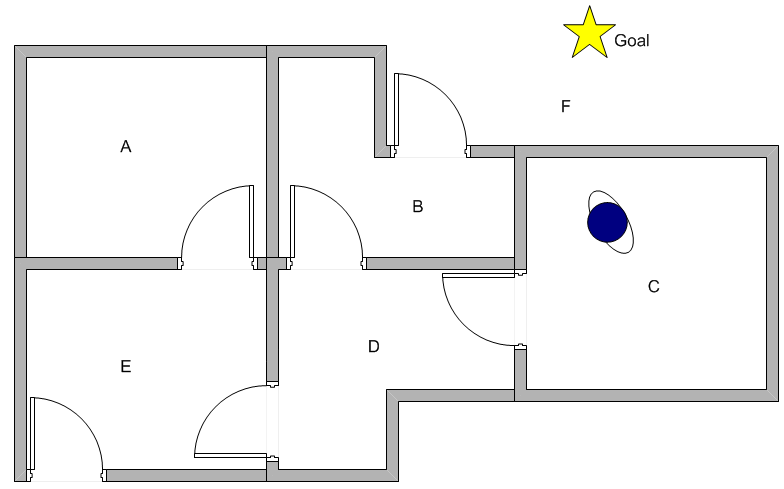
Have a look at the code (it is based on the Matlab code from the same tutorial the picture is from, which is why the names of variables and functions are called the same way to ensure consistency):
# find all possible actions
AllActions <- function(state, R) {
which(R[state, ] >= 0)
}
# chose one action out of all possible actions by chance
PossibleAction <- function(state, R) {
sample(AllActions(state, R), 1)
}
# Q-learning function
UpdateQ <- function(state, Q, R, gamma, goalstate) {
action <- PossibleAction(state, R)
Q[state, action] <- R[state, action] + gamma * max(Q[action, AllActions(action, R)]) # Bellman equation (learning rate implicitly = 1)
if(action != goalstate) Q <- UpdateQ(action, Q, R, gamma, goalstate)
Q
}
# recursive function to get the action with the maximum Q value
MaxQ <- function(state, Q, goalstate) {
action <- which.max(Q[state[length(state)], ])
if (action != goalstate) action <- c(action, MaxQ(action, Q, goalstate))
action
}
# representation of the maze
R <- matrix(c(-Inf, -Inf, -Inf, -Inf, 0, -Inf,
-Inf, -Inf, -Inf, 0, -Inf, 100,
-Inf, -Inf, -Inf, 0, -Inf, -Inf,
-Inf, 0, 0, -Inf, 0, -Inf,
0, -Inf, -Inf, 0, -Inf, 100,
-Inf, 0, -Inf, -Inf, 0, 100), ncol = 6, byrow = TRUE)
colnames(R) <- rownames(R) <- LETTERS[1:6]
R
## A B C D E F
## A -Inf -Inf -Inf -Inf 0 -Inf
## B -Inf -Inf -Inf 0 -Inf 100
## C -Inf -Inf -Inf 0 -Inf -Inf
## D -Inf 0 0 -Inf 0 -Inf
## E 0 -Inf -Inf 0 -Inf 100
## F -Inf 0 -Inf -Inf 0 100
Q <- matrix(0, nrow = nrow(R), ncol = ncol(R))
colnames(Q) <- rownames(Q) <- LETTERS[1:6]
Q
## A B C D E F
## A 0 0 0 0 0 0
## B 0 0 0 0 0 0
## C 0 0 0 0 0 0
## D 0 0 0 0 0 0
## E 0 0 0 0 0 0
## F 0 0 0 0 0 0
gamma <- 0.8 # learning rate
goalstate <- 6
N <- 50000 # no. of episodes
for (episode in 1:N) {
state <- sample(1:goalstate, 1)
Q <- UpdateQ(state, Q, R, gamma, goalstate)
}
Q
## A B C D E F
## A -Inf -Inf -Inf -Inf 400 0
## B 0 0 0 320 0 500
## C -Inf -Inf -Inf 320 0 0
## D 0 400 256 0 400 0
## E 320 0 0 320 0 500
## F 0 400 0 0 400 500
Q / max(Q) * 100
## A B C D E F
## A -Inf -Inf -Inf -Inf 80 0
## B 0 0 0.0 64 0 100
## C -Inf -Inf -Inf 64 0 0
## D 0 80 51.2 0 80 0
## E 64 0 0.0 64 0 100
## F 0 80 0.0 0 80 100
# print all learned routes for all rooms
for (i in 1:goalstate) {
cat(LETTERS[i], LETTERS[MaxQ(i, Q, goalstate)], sep = " -> ")
cat("\n")
}
## A -> E -> F
## B -> F
## C -> D -> B -> F
## D -> B -> F
## E -> F
## F -> F
So again, the algorithm has found the best route for each room!
Recently the combination of Neural Networks (see also Understanding the Magic of Neural Networks) and Reinforcement Learning has become quite popular. For example AlphaGo, the machine from Google that defeated a Go world champion for the first time in history is based on this powerful combination!
3 thoughts on “Reinforcement Learning: Life is a Maze”