

You may have misread the title as the old correlation does not imply causation mantra, but the opposite is also true! If you don’t believe me, read on…
First I want to provide you with some intuition on what correlation is really all about! For many people (and many of my students for sure) the implications of the following formula for the correlation coefficient  of two variables
of two variables  and
and  are not immediately clear:
are not immediately clear:
![\[r=\frac{1}{s_x \cdot s_y}\sum_{i=1}^N \frac{\left( x_i-\bar{x} \right) \left( y_i-\bar{y} \right)}{N}\]](https://blog.ephorie.de/wp-content/ql-cache/quicklatex.com-c419d3ed738fc4a52afea7060693e627_l3.png "Rendered by QuickLaTeX.com")
In fact the most interesting part is this:  . We see a product of two differences. The differences consist of the data points minus the respective means (average values): in effect, this leads to the origin being moved to the means of both variables (as if you moved the crosshairs right into the centre of all data points).
. We see a product of two differences. The differences consist of the data points minus the respective means (average values): in effect, this leads to the origin being moved to the means of both variables (as if you moved the crosshairs right into the centre of all data points).
There are now four possible quadrants for every data point: top or bottom, left or right. Top right means that both differences are positive, so the result will be positive too. The same is true for the bottom left quadrant because minus times minus equals plus (it often boils down to simple school maths)! The other two quadrants give negative results because minus times plus and plus times minus equals minus.
After that, we sum over all products and normalize them by dividing by the respective standard deviations (how much the data are spread out), so that we will only get values between  and
and  .
.
Let us see this in action with an example. First we define a helper function for visualizing this intuition:
cor.plot <- function(data) {
x_mean <- mean(data[ , 1])
y_mean <- mean(data[ , 2])
plot(data, type = "n") # plot invisibly
limits = par()$usr # limits of plot
# plot correlation quadrants
rect(x_mean, y_mean, limits[2], limits[4], col = "lightgreen")
rect(x_mean, y_mean, limits[1], limits[4], col = "orangered")
rect(x_mean, y_mean, limits[1], limits[3], col = "lightgreen")
rect(x_mean, y_mean, limits[2], limits[3], col = "orangered")
points(data, pch = 16) # plot scatterplot on top
colnames(data) <- c("x", "y") # rename cols instead of dynamic variable names in lm
abline(lm(y ~ x, data), lwd = 2) # add regression line
title(paste("cor =", round(cor(data[1], data[2]), 2))) # add cor as title
}
Now for the actual example (in fact the same example we had in this post: Learning Data Science: Modelling Basics):
age <- c(21, 46, 55, 35, 28) income <- c(1850, 2500, 2560, 2230, 1800) data <- data.frame(age, income) plot(data, pch = 16)
cor.plot(data)
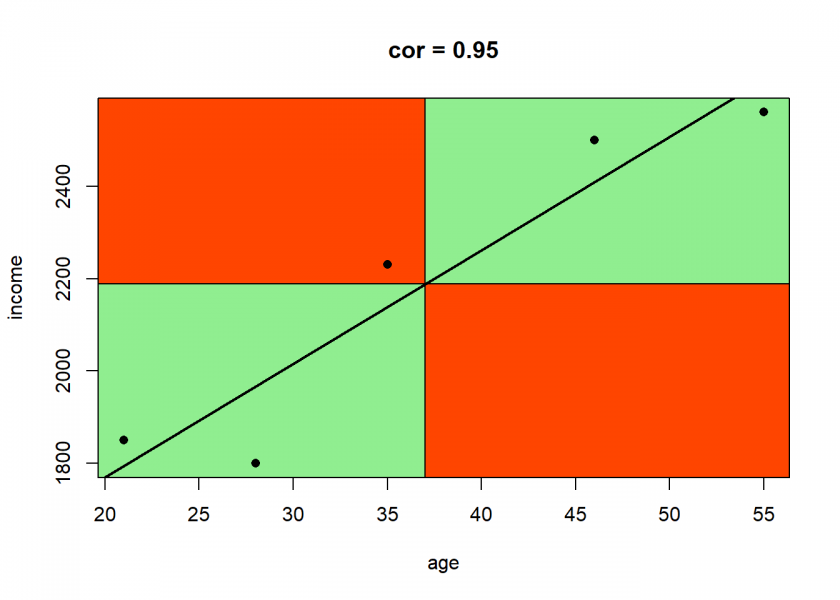
The correlation is very high because most of the data points are in the positive (green) quadrants and the data is close to its regression line (linear regression and correlation are closely related mathematically).
Now, let us get to the actual topic of this post: Causation doesn’t imply Correlation either. What could be “more causal” than a parabolic shot? When you shoot a projectile without air resistance the trajectory will form a perfect parabola! This is in fact rocket science!
Let us simulate such a shot and calculate the correlation between time and altitude, two variables that are perfectly causally dependent:
t <- c(-30:30) x <- -t^2 data <- data.frame(t, x) plot(data, pch = 16)
cor.plot(data)
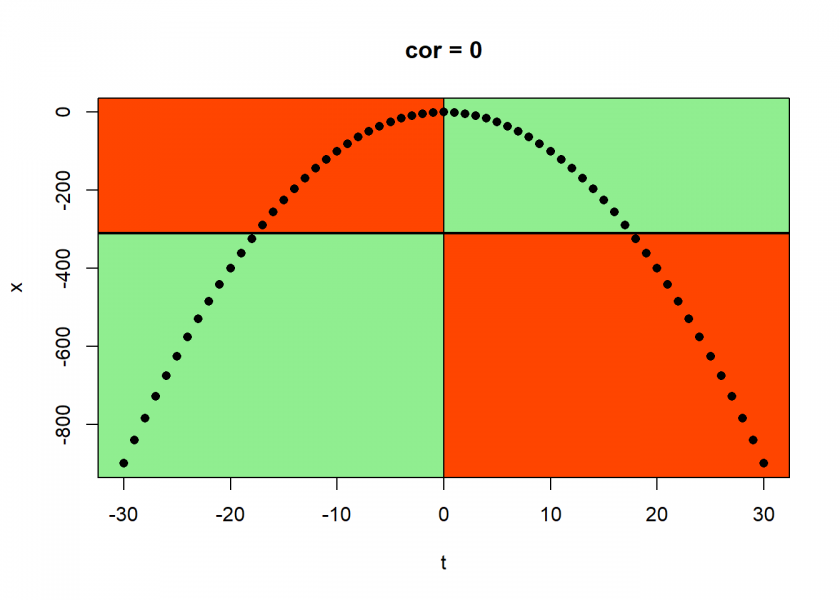
The correlation is exactly zero, zip, nada! And it is clear why: the data points in the positive and in the negative quadrants cancel each other out completely because of the perfect symmetry!
This leads us to the following very important insight:
Correlation is a measure of linear dependence (and linear dependence only!).
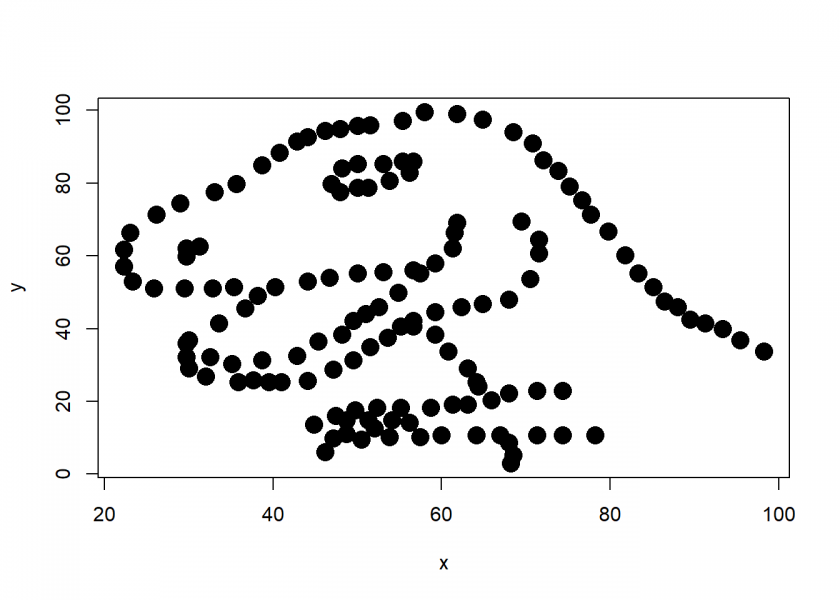
Even a strong causal relationship can be overlooked by correlation because of its non-linear nature (as in this case with the quadratic relationship). The following example conveys the same idea in a somewhat more humorous manner – it is the by now infamous datasaurus:
library(datasauRus) # on CRAN dino <- datasaurus_dozen[datasaurus_dozen$dataset == "dino", 2:3] plot(dino, pch = 16, cex = 2)
cor.plot(dino)
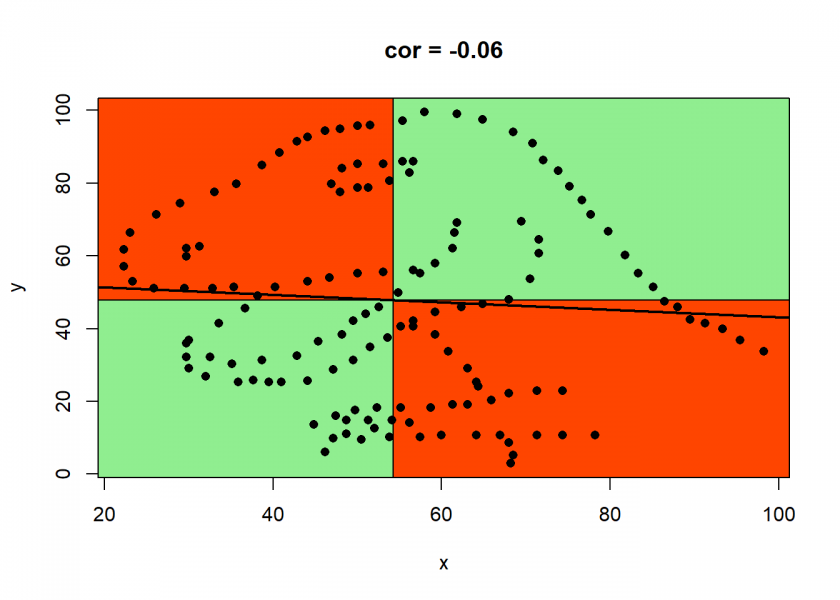
As with the above example, we can clearly see why the correlation is so low, although there is a whole dinosaur hiding in your data…
The learning is that you should never just blindly trust statistical measures on their own, always visualize your data when possible: there might be some real beauties hiding inside your data, waiting to be discovered…
UPDATE November 9, 2022
I created a video for this post (in German):
Incorrect headline. By not specifying linear correlation your initial statement is wrong. Period. Explicit notation is important when your statement doesn’t generalize.
Dear Mm: Thank you for your comment.
No. 1: when people speak of correlation they almost always refer to linear correlation by convention.
No. 2: your comment would imply that there is at least one non-linear correlation measure that can reliably detect causality… I’d be happy if you could share this measure with us.
I would argue that my headline holds for any correlation measure. You would of course need different counterexamples than given in the text but that is a triviality.
The headline is wrong. Correlation is a broad term that just means “statistical association”: any statistical relationship. But you are talking specifically about Pearson’s linear correlation coefficient. That is very misleading.
1. You may know the great webpage called “Spurious Correlations” (https://www.tylervigen.com/spurious-correlations). If “correlation” was generally understood as “linear correlation”, as you are trying to argue, then nobody would understand that webpage, because most of the correlations shown there are non-linear. So that’s not true. Correlation is generally understood in the broad sense: as something following something.
2. Even the Wikipedia page about “Correlation and dependence” has an outstanding explanation of what a correlation is, and describes and references several correlation measurements that are specifically designed to deal with general relationships. There are also several R packages that provide a functions to compute non-linear correlations.
Dear Iñaki: Thank you for your comment.
1. Of course I know the webpage, I regularly use it in my lectures. Indeed it is a great example that underlines my point: that webpage exclusively deals with linear correlation. Just look at the numbers given: it is r in every single example which is nothing else than the Pearson correlation coefficient (where you can find the definition above).
2. I know that there are non-linear correlation measures (see e.g. my answer on distance correlation here from 2012: Quant SE), yet I see no way how they would be able to spot causality reliably. You might want to remember that causality is notoriously hard to spot… no single measure would cover all cases.
While it is true that I use the conventionally used linear correlation in the article the following statement would also hold: “Causation doesn’t imply non-linear Correlation either” – you would always be able to find counterexamples where a causal process gives near zero non-linear correlation (e.g. in my linked answer just look at the bottom right example!)
1. The plots provide a Pearson’s correlation coefficient, but if you explore all the plots, many of them (probably “most” was excessive in my previous comment) are just r=0.6, but still you see a pattern, many times because there is some higher order relationship (e.g., quadratic).
2. No correlation measurement can spot causality, linear or non-linear.
Causation imply some kind of relationship. If there’s no relationship, there cannot be causation. Correlation is “some kind of relationship”.
Dear Iñaki: Thank you, we can certainly agree on that.
I think in the end it is a matter of interpretation: if you interpret correlation in the sense of “some kind of relationship” than the headline is at least misleading, if you interpret it as a specific measure (linear or non-linear) than the headline is correct.
Can’t agree more.
Ignore the haters… I love this article. It’s fresh and upbeat and ALMOST too mathy for lay people but just right. Good job! I love the visual of green and red! Keep up the good work!
Dear Amit: Thank you for your kind words, I really appreciate that!
I wouldn’t call them haters, some people are just very compassionate about their subject.
There are many more posts to come, so stay tuned!
There is now a way in R to compute causal direction using R package generalCorr. Here is the code
t <- c(-30:30)
x causeSummary(cbind(t,x))
[1] t causes x strength= 68.504
[1] corr= 0 p-val= 1
cause response strength corr. p-value
[1,] “t” “x” “68.504” “0” “1”
This shows that for the rocket science example, strong causal link is indicated from t to x
The package has been widely applied in many fields, Vignettes give the cites from reputed journals.
Thank you very much, Hrishikesh – I didn’t know your package yet… it looks very promising and I will definitely try it out!
This is a fantastic and illustrative article. If your intent was to shout out and show so caveats about this often misused metric, you did a very good job.
Thank you for your time and effort.
Thank you for your great feedback, Manuel – I really appreciate it.
For fear of being labeled a Post Hoc Failure, causation implies (requires?) temporal consistency. Yes? I am unaware of stat functions which enforce such ‘relationship’.
What do you mean by “temporal consistency” and “enforcement” of it? Could you give an example? Thank you.
If over an interval symmetric around the origin one take x and y= |x| (absolute value) then corr(x,y) = 0 and, of course, there is a causal relationship between x and y . Hard to do better than that.
i thought this was going to be a story about x causing y, but there being a confounder z which just offsets the linear relationship between x and y leading to cor(x,y)=0. still the issue of linearity is an important point.
Good web site you have here.. It’s hard to find quality writing like yours nowadays.
I seriously appreciate individuals like you!
Take care!!