

During this time of year, there is obviously a lot of talk about the Bible. As most people know the New Testament comprises four different Gospels written by anonymous authors 40 to 70 years after Jesus’ supposed crucifixion.
Unfortunately, we have lost all of the originals but only retained copies of copies of copies (and so on) which date back hundreds of years after they were written in all kinds of different versions (renowned Biblical scholar Professor Bart Ehrmann states that there are more versions of the New Testament than there are words in the New Testament). Just as a fun fact: there are many more Gospels but only those four were included in the “official” Bible.
So, in general, it is interesting to learn a little bit more about this stuff, especially because, for better or worse, it is at the core of Western civilization. One interesting question is how do the four Gospels relate to each other. To find that out you could either study Greek (i.e. the language of the New Testament) and Christian theology for many years and decades – or you could use Natural Language Processing (NLP) in the form of the stylo package and do a cluster analysis within seconds (to learn about clustering see this post here: Learning Data Science: Understanding and Using k-means Clustering). Obviously, we go for the latter…
For that matter, we download one version of the four Gospels from Project Gutenberg in Greek and put it into a separate directory called ‘corpus’ (which is the name of the default directory of the package). The famous beginning of the Gospel of John (“In the beginning was the Word, and the Word was with God, and the Word was God…”) reads as follows in Greek:
Στην αρχή ‘ταν ο λόγος κι’ ο λόγος είτανε με το
Θεό και Θεός είταν ο λόγος. Είταν εκείνος στην αρχή
με το Θεό. Όλα τα πάντα μέσο του έγιναν, και χωρίς
του τίποτα δεν έγινε που γίνηκε. Μέσα του είτανε ζωή
κι’ η ζωή ‘τανε το φως των ανθρώπων, και το φως
μέσα στο σκοτάδι φέγγει και το σκοτάδι δεν το κυρίεψε.
For your convenience I provide you with the curated texts here: John, Luke, Mark, Matthew.
After that we can already call the main function of the package:
library(stylo)
## ### stylo version: 0.6.8 ###
##
## If you plan to cite this software (please do!), use the following reference:
## Eder, M., Rybicki, J. and Kestemont, M. (2016). Stylometry with R:
## a package for computational text analysis. R Journal 8(1): 107-121.
## <https://journal.r-project.org/archive/2016/RJ-2016-007/index.html>
##
## To get full BibTeX entry, type: citation("stylo")
stylo(corpus.lang = "Other", encoding = "UTF-8", mfw.min = 200, mfw.max = 200, custom.graph.title = "Ancient Greek Gospels", gui = FALSE)
## using current directory...
## Performing no sampling (using entire text as sample)
## loading John.txt ...
## loading Luke.txt ...
## loading Mark.txt ...
## loading Matthew.txt ...
## slicing input text into tokens...
##
## turning words into features, e.g. char n-grams (if applicable)...
##
## Total nr. of samples in the corpus: 4
## ....
## The corpus consists of 70943 tokens
##
## processing 4 text samples
##
## combining frequencies into a table...
##
##
## culling @ 0 available features (words) 5000
## Calculating z-scores...
##
## Calculating classic Delta distances...
## MFW used:
## 200
##
## Function call:
## stylo(gui = FALSE, corpus.lang = "Other", encoding = "UTF-8", mfw.min = 200, mfw.max = 200, custom.graph.title = "Ancient Greek Gospels")
##
## Depending on your chosen options, some results should have been written
## into a few files; you should be able to find them in your current
## (working) directory. Usually, these include a list of words/features
## used to build a table of frequencies, the table itself, a file containing
## recent configuration, etc.
##
## Advanced users: you can pipe the results to a variable, e.g.:
## I.love.this.stuff = stylo()
## this will create a class "I.love.this.stuff" containing some presumably
## interesting stuff. The class created, you can type, e.g.:
## summary(I.love.this.stuff)
## to see which variables are stored there and how to use them.
##
##
## for suggestions how to cite this software, type: citation("stylo")
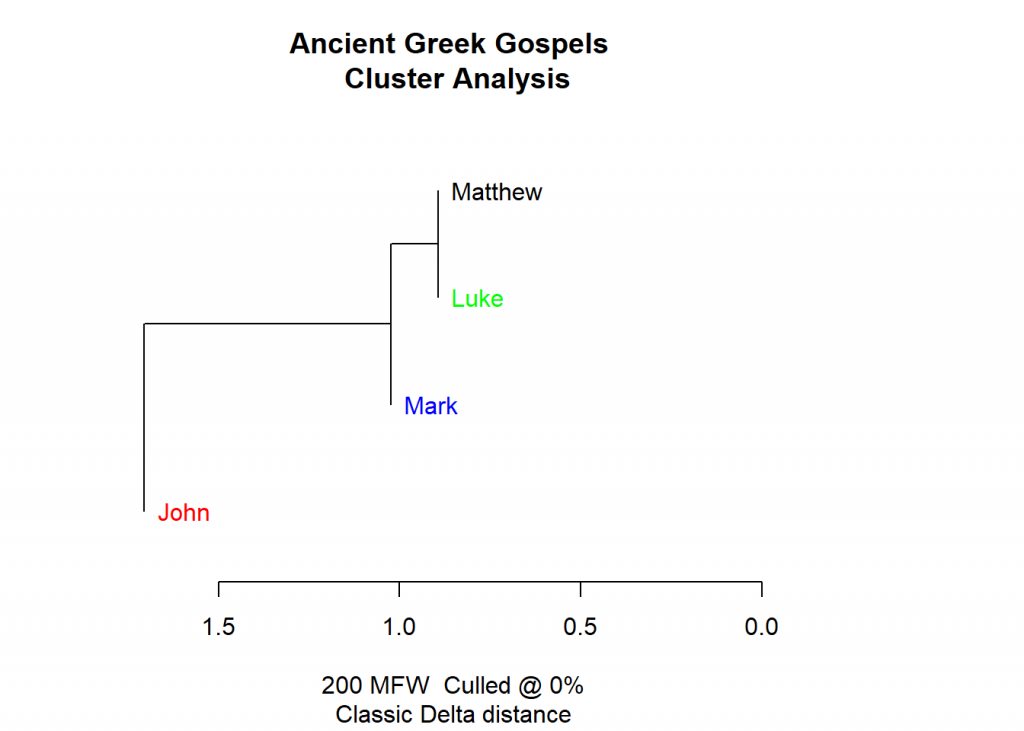
As you can see the Gospels of Matthew and Luke are more similar than Mark (the oldest Gospel), John (the last Gospel that made it into the Bible) is farthest away. This is indeed what Biblical scholars have found out by diligently studying the New Testament: Mark, Luke, and Matthew are called “Synoptic Gospels” because they are so similar, John kind of stands on its own. The shared pieces of the Synoptic Gospels can be seen here (picture from Wikipedia, Synoptic Gospels):
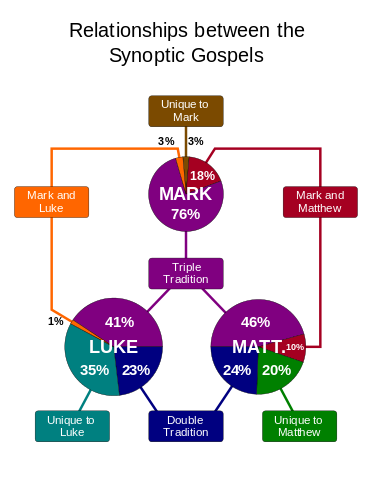
As you can see, Biblical scholars have found out that Luke and Matthew share about 60 to 70 percent of the text (through the so-called double tradition), whereas Mark shares about 40 percent of the text (through the triple tradition). For comparison, John only shares about 10 percent with the synoptic Gospels. Now, this is exactly what our cluster analysis form above shows – what an impressive feat!
By the way, there is an even simpler way to interact with the stylo package: through the GUI. Just call stylo() and the following window will open where you can play around with different arguments:
It has never been easier to do sophisticated textual analyses, even in ancient languages one cannot understand! You might ask: how did R do that?
Well, behind the scenes R basically creates frequency tables for the words used in the different documents. It then tries to cluster the documents based on a similarity (or distance) measure. Intuitively that means that the more often authors use the same words the closer their texts are. As you can see R doesn’t really have to understand the words or the language used. It just maps statistical measures which seems to be quite effective (not only) in this case. The statistical measures often give some kind of characteristic signature of an author or a source. In a way, this is the quantified version of fuzzy concepts like ‘writing style’ yet R can do it much more quickly even for long texts than any human ever could!
Happy New Year… stay tuned for much more to come in

Hi,
Thank you for the example that you shared. Indeed, the package seems to be quite powerful. However, knowing the Greek language I could not resist having a quick look at the texts that your links pointed to (including the text from John). What I can say, and I am quite sure of that, is that the language in all texts is not ancient Greek. Moreover, it is not correct modern Greek either.
These two are facts. What I can deduce from reading them is that they have probably come from an automated translating engine. If the latter is the case, I would think that the plurality of the natural language was missed (the Greek language is very rich in words) and the limitations of the engine could have biased the text-similarity analysis.
Great Petros! Analytical methods are important but the data are paramount!
Hi
You’re right. They are neither classical Greek of say 500 to 400 BC nor modern Greek. They are what is called koine Greek, the lingua franca of much of the Eastern Mediterranean at the time of Christ. Palestinian Jews of the time spoke Aramaic, and the traditions about Jesus would have first circulated in that language, but the missions to the Gentiles used koine.
Interesting, didn’t know that either and changed it in the post (not in the plot though).
Wikipedia gives a good overview (as always): https://en.wikipedia.org/wiki/Koine_Greek
I was rather baffled at the text as well. I’m quite familiar with Koine Greek and the New Testament in Koine Greek specifically – I studied theology in university before making a career switch into data science – and it certainly doesn’t seem like Koine Greek to me either. So looking up the text at the Project Gutenberg website, it appears to be a translation to modern Greek, albeit one published in 1902, which maybe means it’s rather archaic and would confuse people who are familiar with modern Greek; there have been very different standardized versions of modern Greek in the 19th and 20th century, so somebody in 1902 might have written a very different ‘modern’ Greek compared to somebody today, see: https://en.wikipedia.org/wiki/Varieties_of_Modern_Greek#Roots_and_history:_Demotic_and_Katharevousa
I assume you used this https://www.gutenberg.org/files/31802/31802-h/31802-h.htm
which states at the beginning that it was translated by Alexandros Pallis, whom wikipedia confirms to be a Greek scholar who translated the new testament into modern Greek. https://en.wikipedia.org/wiki/Alexandros_Pallis
For the standard Koine Greek version used in biblical scholarship see:
http://www.nestle-aland.com/en/read-na28-online/
Anyway, thanks for this example, I enjoyed seeing a standard hypothesis of new testament scholarship be supported by a clustering algorithm! Having a background in theology and now working in data science, seeing the two somehow come together was quite nice 🙂
Thank you… ok, so I changed the post again. I didn’t expect this to turn into a discussion on different dialects of Greek. We had all variants now: Ancient, Koine and ‘modern’ (around 1900) Greek plus (as a bonus 😉 ) machine translated Greek.
Learned a lot along the way, one of the reasons why I started this blog… so thank you again!
Excellent – thank you!
I have looked at the New Testament as a whole and found some interesting graphs, especially as I tried to consider the scholarly suggested authorship of each book. I would be keen to find a site with the Koine Greek books which allow download of the full books. Thank you again.
Dear Bob: Thank you for your kind words! Where did you find the graphs? Could you provide some links? Or did you create them yourselfs? Have you published something on the matter?
The NT in Koine Greek: I did a little digging and have to say that it seems to be surprisingly hard to find something useful here… this is especially surprising considering the fact that you can find hundreds of sites with all kinds of fancy translations (even into non-existent languages! See here: https://en.wikipedia.org/wiki/Bible_translations_into_fictional_languages).
When you find a usable version please let me know. Thank you again
Edit: Just saw your blog post (see pingback below)… very interesting!
Yes if I find anything I’ll pass on the details. I think the analysis sheds light into the matter and hopes to support other opinion from other techniques. Thank you
Latest look at the Gospel of John hasn’t revealed much I’m afraid. https://dbobstoner.wordpress.com/2019/05/16/analysing-johns-gospel/
I had hoped that the new source might help, but the results do not show significant differences. I have found the latest R Stylo function difficult to utilise on the Mac, hence resorted to Linux.
Thank you again for starting me on this thread!