

What is the “opposite” of sampling without replacement? In a classical urn model sampling without replacement means that you don’t replace the ball that you have drawn. Therefore the probability of drawing that colour becomes smaller. How about the opposite, i.e. that the probability becomes bigger? Then you have a so-called Pólya urn model!
Many real-world processes have this self-reinforcing property, e.g. leading to the distribution of wealth or the number of followers on social media. If you want to learn how to simulate such a process with R and encounter some surprising results, read on!
Continue reading “The Pólya Urn Model: A simple Simulation of “The Rich get Richer””




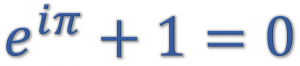

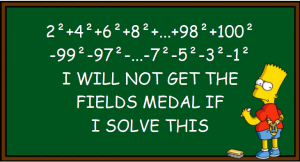 This time we want to solve the following simple task with R: Take the numbers 1 to 100, square them, and add all the even numbers while subtracting the odd ones!
This time we want to solve the following simple task with R: Take the numbers 1 to 100, square them, and add all the even numbers while subtracting the odd ones!
