

One of the topics that is totally hyped at the moment is obviously Artificial Intelligence or AI for short. There are many self-proclaimed experts running around trying to sell you the stuff they have been doing all along under this new label.
When you ask them what AI means you will normally get some convoluted explanations (which is a good sign that they don’t get it themselves) and some “success stories”. The truth is that many of those talking heads don’t really know what they are talking about, yet happen to have a friend who knows somebody who picked up a book at the local station bookshop… ok, that was nasty but unfortunately often not too far away from the truth.
So, what is AI really? This post tries to give some guidance, so read on!
The traditional way coding a computer program worked was through carefully analyzing the problem, trying to separate its different parts into simpler sub-problems, put the solution into an algorithmic form (kind of a recipe), and finally code it. Let’s have a look at an example!
Let’s say you want to program an app for mushroom pickers with warnings for certain qualities. The idea is to find an easy to follow guide in the form of “if your mushroom has this quality then DO NOT eat it!” (in computer lingo called “conditional statements” or just “conditionals”). As any mushroom picker can attest this is not an easy task. For the matter have a look at the following dataset (you can find it here: mushrooms, originally it is from https://archive.ics.uci.edu/ml/datasets/mushroom):
mushrooms <- read.csv("data/mushrooms.csv") # change path accordingly
str(mushrooms)
## 'data.frame': 8124 obs. of 23 variables:
## $ cap_shape : Factor w/ 6 levels "bell","conical",..: 3 3 1 3 3 3 1 1 3 1 ...
## $ cap_surface : Factor w/ 4 levels "fibrous","grooves",..: 4 4 4 3 4 3 4 3 3 4 ...
## $ cap_color : Factor w/ 10 levels "brown","buff",..: 1 10 9 9 4 10 9 9 9 10 ...
## $ bruises : Factor w/ 2 levels "no","yes": 2 2 2 2 1 2 2 2 2 2 ...
## $ odor : Factor w/ 9 levels "almond","anise",..: 8 1 2 8 7 1 1 2 8 1 ...
## $ gill_attachment : Factor w/ 2 levels "attached","free": 2 2 2 2 2 2 2 2 2 2 ...
## $ gill_spacing : Factor w/ 2 levels "close","crowded": 1 1 1 1 2 1 1 1 1 1 ...
## $ gill_size : Factor w/ 2 levels "broad","narrow": 2 1 1 2 1 1 1 1 2 1 ...
## $ gill_color : Factor w/ 12 levels "black","brown",..: 1 1 2 2 1 2 5 2 8 5 ...
## $ stalk_shape : Factor w/ 2 levels "enlarging","tapering": 1 1 1 1 2 1 1 1 1 1 ...
## $ stalk_root : Factor w/ 5 levels "bulbous","club",..: 3 2 2 3 3 2 2 2 3 2 ...
## $ stalk_surface_above_ring: Factor w/ 4 levels "fibrous","scaly",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ stalk_surface_below_ring: Factor w/ 4 levels "fibrous","scaly",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ stalk_color_above_ring : Factor w/ 9 levels "brown","buff",..: 8 8 8 8 8 8 8 8 8 8 ...
## $ stalk_color_below_ring : Factor w/ 9 levels "brown","buff",..: 8 8 8 8 8 8 8 8 8 8 ...
## $ veil_type : Factor w/ 1 level "partial": 1 1 1 1 1 1 1 1 1 1 ...
## $ veil_color : Factor w/ 4 levels "brown","orange",..: 3 3 3 3 3 3 3 3 3 3 ...
## $ ring_number : Factor w/ 3 levels "none","one","two": 2 2 2 2 2 2 2 2 2 2 ...
## $ ring_type : Factor w/ 5 levels "evanescent","flaring",..: 5 5 5 5 1 5 5 5 5 5 ...
## $ spore_print_color : Factor w/ 9 levels "black","brown",..: 1 2 2 1 2 1 1 2 1 1 ...
## $ population : Factor w/ 6 levels "abundant","clustered",..: 4 3 3 4 1 3 3 4 5 4 ...
## $ habitat : Factor w/ 7 levels "grasses","leaves",..: 5 1 3 5 1 1 3 3 1 3 ...
## $ type : Factor w/ 2 levels "edible","poisonous": 2 1 1 2 1 1 1 1 2 1 ...
head(mushrooms)
## cap_shape cap_surface cap_color bruises odor gill_attachment
## 1 convex smooth brown yes pungent free
## 2 convex smooth yellow yes almond free
## 3 bell smooth white yes anise free
## 4 convex scaly white yes pungent free
## 5 convex smooth gray no none free
## 6 convex scaly yellow yes almond free
## gill_spacing gill_size gill_color stalk_shape stalk_root
## 1 close narrow black enlarging equal
## 2 close broad black enlarging club
## 3 close broad brown enlarging club
## 4 close narrow brown enlarging equal
## 5 crowded broad black tapering equal
## 6 close broad brown enlarging club
## stalk_surface_above_ring stalk_surface_below_ring stalk_color_above_ring
## 1 smooth smooth white
## 2 smooth smooth white
## 3 smooth smooth white
## 4 smooth smooth white
## 5 smooth smooth white
## 6 smooth smooth white
## stalk_color_below_ring veil_type veil_color ring_number ring_type
## 1 white partial white one pendant
## 2 white partial white one pendant
## 3 white partial white one pendant
## 4 white partial white one pendant
## 5 white partial white one evanescent
## 6 white partial white one pendant
## spore_print_color population habitat type
## 1 black scattered urban poisonous
## 2 brown numerous grasses edible
## 3 brown numerous meadows edible
## 4 black scattered urban poisonous
## 5 brown abundant grasses edible
## 6 black numerous grasses edible
The dataset consists of 8124 examples of mushrooms with 22 qualities each (plus the attribute of whether the respective mushroom is edible or poisonous). Well, obviously this is not going to be easy…
A naive approach would be to formulate rules for every instance: if the cap shape is convex and the cap surface smooth and the cap colour brown… and so on for all 22 attributes, then DO NOT eat it! This would obviously not be very helpful. Another approach would be to go through every attribute and see whether it is helpful in determining the type, so for example:
table(mushrooms$cap_shape, mushrooms$type) ## ## edible poisonous ## bell 404 48 ## conical 0 4 ## convex 1948 1708 ## flat 1596 1556 ## knobbed 228 600 ## sunken 32 0
Obviously, this attribute isn’t very helpful, in many cases, it just gives a “maybe, maybe not”-answer. Perhaps the approach itself is not so bad after all but you would have to try it for all 22 attributes, interpret the results, pick the best one, formulate if-then-rules and code them… tiresome and error-prone.
Wouldn’t it be nice to do it the other way around: just show the computer all of the examples and it magically programs itself by finding the appropriate if-then-rules automatically?

This is what AI is all about:
Artificial Intelligence (AI): Showing a computer examples of a problem so that it programs itself to solve it.
…or as a meme:
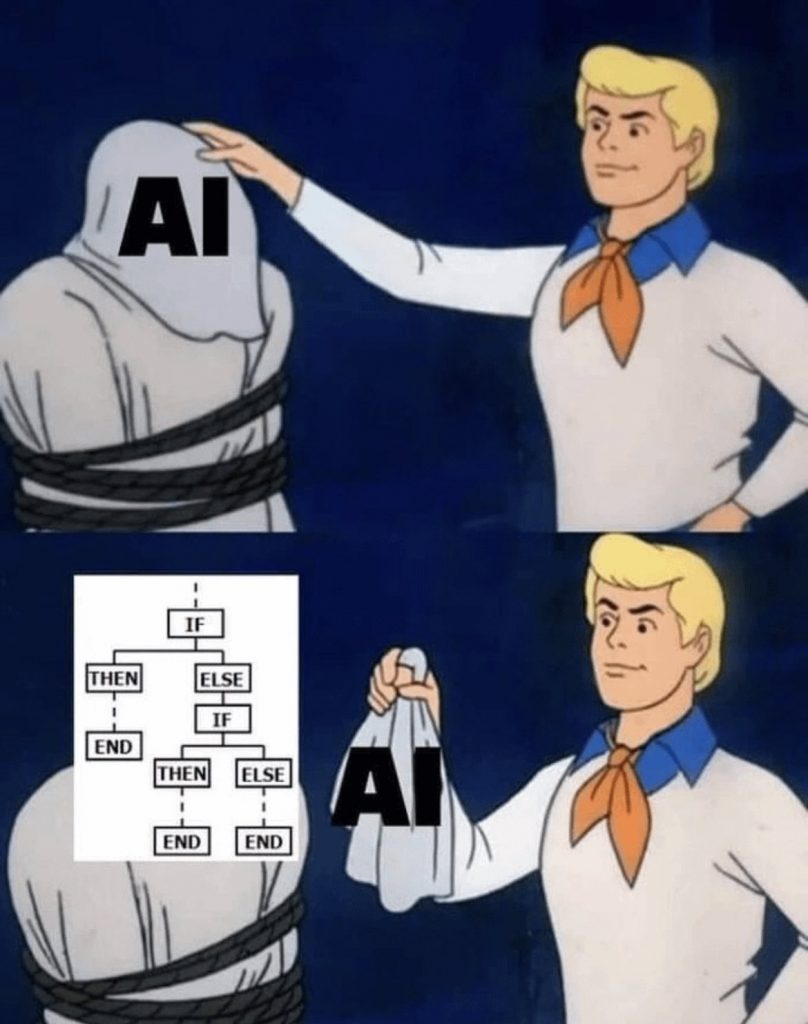
The found solutions are often even better than what even the best programmers could have achieved, or put another way, AI is often better at learning than we are at teaching computers to solve a problem!
(To be precise this is supervised learning, which is a subset of machine learning, which is itself a subset of artificial intelligence. This is the dominant form of most artificial intelligence applications so that it is often used interchangebly. To understand the different concepts better, please consult The Most Advanced AI in the World explains what AI, Machine Learning, and Deep Learning are!… which was itself written by an AI!)
So, let us throw AI at our problem in the form of the OneR package (on CRAN):
library(OneR) OneR(mushrooms, verbose = TRUE) ## ## Attribute Accuracy ## 1 * odor 98.52% ## 2 spore_print_color 86.8% ## 3 gill_color 80.5% ## 4 ring_type 77.55% ## 5 stalk_surface_above_ring 77.45% ## 6 stalk_surface_below_ring 76.61% ## 7 gill_size 75.63% ## 8 bruises 74.4% ## 9 population 72.18% ## 10 stalk_color_above_ring 71.64% ## 11 stalk_color_below_ring 71.44% ## 12 habitat 69.03% ## 13 stalk_root 64.6% ## 14 gill_spacing 61.6% ## 15 cap_color 59.53% ## 16 cap_surface 58.05% ## 17 cap_shape 56.43% ## 18 stalk_shape 55.29% ## 19 ring_number 53.82% ## 20 veil_color 51.9% ## 21 gill_attachment 51.8% ## 21 veil_type 51.8% ## --- ## Chosen attribute due to accuracy ## and ties method (if applicable): '*' ## ## Call: ## OneR.data.frame(x = mushrooms, verbose = TRUE) ## ## Rules: ## If odor = almond then type = edible ## If odor = anise then type = edible ## If odor = creosote then type = poisonous ## If odor = fishy then type = poisonous ## If odor = foul then type = poisonous ## If odor = musty then type = poisonous ## If odor = none then type = edible ## If odor = pungent then type = poisonous ## If odor = spicy then type = poisonous ## ## Accuracy: ## 8004 of 8124 instances classified correctly (98.52%)
Wow! Within the blink of an eye and with just one command (OneR) we got all the rules we need for our app! It is the odour: if it smells poisonous it probably is. The accuracy of this is nearly 99%, not too bad for such a simple rule… we wouldn’t even need an app for that.
For more examples, some deeper explanation (and even a video) on the OneR package go here: OneR – Establishing a New Baseline for Machine Learning Classification Models.
By the way, in the words “programs itself” – impressive as it may be – is still the term “programming”, so we are not talking about machines developing intentions, feelings, or even consciousness anytime soon. This is the domain of Hollywood and not AI!
As with every hype, there are many terms flying around, like Machine Learning (ML), Data Science and (Predictive) Analytics and somewhat older terms, like Data Mining, Knowledge Discovery, and Business Intelligence… and many, many more. Of course, you can define them in all sorts of ways but to be honest with you in essence they all mean the same (see definition above). I would argue that Data Science is a somewhat broader term that comprises also e.g. the handling of data, interpretation by domain experts and presentation to the business but that is just one definition. There is an old joke that what is Machine Learning when put on PowerPoint becomes Artificial Intelligence – it just sounds so much better than any technical term.
We can now answer another question: why now? Why is there such a hype now? I will share a secret with you: most of the AI methods used today are quite old! For example, the core principles of (artificial) neural networks (a.k.a. deep learning) are from the ’60s of the last century! Now, more than half a century later we’ve got the hype. The reason is:
It’s the data, stupid!
Because AI is all about learning from examples, we need lots and lots of data and because of the internet and mobile revolution, we are now drowning in those data. Combine this with more and more powerful hardware (also in the form of cheap cloud services) and you’ve got a revolution at your hands.
And there is yet another lesson to be learned: when I said “we” are drowning in data it was not entirely correct: tech companies like Google, Amazon, Facebook, Apple (GAFA) and their Chinese counterparts, like Baidu, Alibaba, and Tencent (BAT) are drowning in our (!) data. This is the reason why they are also leading the field of AI and not because they necessarily have the brightest AI geniuses.
This point is best illustrated by the example of DeepL: a small German startup in the area of machine translation. Many tests conducted by professional translators came to the conclusion that the translations by DeepL are far better than any other machine translations (like Google Translate). Why? Not because there necessarily is a secret sauce in their algorithms but because the company behind it (Linguee) had been amassing hand-curated bilingual language pairs for many, many years. The quality of their data is just so much better than of all the other translation services out there. This is their main differentiator.
That is not to say that there haven’t been any major developments in the area of AI algorithms or computer hardware or that you don’t need bright people to set up and finetune those systems (quite to the contrary!) but many of the algorithms are open-source and computing power is relatively cheap via cloud services and, yes, there is a shortage of good people at the moment but there are still many highly qualified data scientists around: the real difference is in (the quality and amount of) the data!
One last thing: many people think that AI is more objective than humans, after all, it’s maths and cool logic, right? Wrong! When you only learn from examples and the examples given are racist the learned rules will be racist too! A very good book on the subject is Weapons of Math Destruction by Cathy O’Neal.
Hope that this gave you some perspective on the ongoing hype… perhaps hype is not such a good word after all because when you look at the underlying reasons you can see that this megatrend is here to stay!
UPDATE May 28, 2022
I created a video for this post (in German):
Awesome information and your insights are spot on about input and output biases. Thank you.
Thank you, Evelyn – I really appreciate it!
Es un articulo estupendo, ya había pensado, que lo que se pretende ahora es asignar nuevos nombres a la la estadística, y a sus métodos englobarlos usando términos nuevos que atraen y estimulan a fijarse en ellos. Indudablemente que esos métodos antiguos han evolucionado, y con ayuda de software se ha posibilitado su uso.
Saludos, Julio.
I don’t speak Spanish so I used DeepL:
“It is a wonderful article, I had already thought, that what we are trying now is to assign new names to statistics, and to their methods to include them using new terms that attract and stimulate you to notice them. Undoubtedly, these old methods have evolved, and with the help of software their use has been made possible.
Greetings, Julio.”
Thank you, Julio, for your great feedback!
great read! I agree with Julio in that AI and its actual cog, ML, are hyped stats
Dear Professor,
I just found a video about an AI making a car. What do you think about it? Here is the youtube-link:
https://www.youtube.com/watch?v=VdG4gUTowXc&ab_channel=DonutMedia
I would be very interested about your opinion about that.
Best regards
Thank you Professor for once again lowering the hype around AI with clear arguments.
And indeed the importance of data in all models is key. How about this recent opinion from Andrew Ng that companies should be more “Data Centric” rather than “Model Centric” ? Which is just the fundamental idea of your blog.
https://analyticsindiamag.com/big-data-to-good-data-andrew-ng-urges-ml-community-to-be-more-data-centric-and-less-model-centric/
Thanks again,
Carlos.