

One of the big sensations of the UEFA Euro 2020 is that Switzerland kicked out world champion France. We take this as an opportunity to share with you a simple statistical model to predict football (soccer) results with R, so read on!
Continue reading “Euro 2020: Will Switzerland kick out Spain too?”
Category: Learning R
Posts about learning R
R Coding Challenge: 7 (+1) Ways to Solve a Simple Puzzle
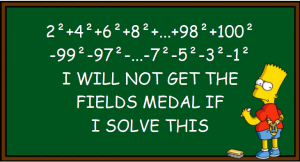 This time we want to solve the following simple task with R: Take the numbers 1 to 100, square them, and add all the even numbers while subtracting the odd ones!
This time we want to solve the following simple task with R: Take the numbers 1 to 100, square them, and add all the even numbers while subtracting the odd ones!
If you want to see how to do that in at least seven different ways in R, read on!
Continue reading “R Coding Challenge: 7 (+1) Ways to Solve a Simple Puzzle”
Learning R: Creating Truth Tables

A short one for today: in this post we will learn how to easily create truth tables with R and will contribute our code to the growing repository of Rosetta code. I hope that you will learn a few tricks along the way, so read on!
Continue reading “Learning R: Creating Truth Tables”
Learning Statistics: On Hot, Cool, and Large Numbers

My father-in-law used to write down the numbers drawn on the lottery to find patterns, especially whether some numbers were “due” because they hadn’t been drawn for a long time. He is not alone! And don’t they have a point? Shouldn’t the numbers balance after some time? Read on to find out!
Continue reading “Learning Statistics: On Hot, Cool, and Large Numbers”
The Solution to my Viral Coin Tossing Poll
 Some time ago I conducted a poll on LinkedIn that quickly went viral. I asked which of three different coin tossing sequences were more likely and I received exactly 1,592 votes! Nearly 48,000 people viewed it and more than 80 comments are under the post (you need a LinkedIn account to fully see it here: LinkedIn Coin Tossing Poll).
Some time ago I conducted a poll on LinkedIn that quickly went viral. I asked which of three different coin tossing sequences were more likely and I received exactly 1,592 votes! Nearly 48,000 people viewed it and more than 80 comments are under the post (you need a LinkedIn account to fully see it here: LinkedIn Coin Tossing Poll).
In this post I will give the solution with some background explanation, so read on!
Continue reading “The Solution to my Viral Coin Tossing Poll”
Recidivism: Identifying the Most Important Predictors for Re-offending with OneR

In 2018 the renowned scientific journal science broke a story that researchers had re-engineered the commercial criminal risk assessment software COMPAS with a simple logistic regression (Science: The accuracy, fairness, and limits of predicting recidivism).
According to this article, COMPAS uses 137 features, the authors just used two. In this post, I will up the ante by showing you how to achieve similar results using just one simple rule based on only one feature which is found automatically in no-time by the OneR package, so read on!
Continue reading “Recidivism: Identifying the Most Important Predictors for Re-offending with OneR”
Parrondo’s Paradox in Finance: Combine two Losing Investments into a Winner

Wikipedia defines Parrondo’s paradox in game theory as
A combination of losing strategies becomes a winning strategy.
If you want to learn more about this fascinating topic and see an application in finance, read on!
Continue reading “Parrondo’s Paradox in Finance: Combine two Losing Investments into a Winner”
Pseudo-Randomness: Creating Fake Noise

In data science, we try to find, sometimes well-hidden, patterns (= signal) in often seemingly random data (= noise). Pseudo-Random Number Generators (PRNG) try to do the opposite: hiding a deterministic data generating process (= signal) by making it look like randomness (= noise). If you want to understand some basics behind the scenes of this fascinating topic, read on!
Continue reading “Pseudo-Randomness: Creating Fake Noise”
How to be Successful! The Role of Risk-taking: A Simulation Study

When you ask successful people for their advice on how to become successful you will often hear that you have to take risks, often huge risks.
In this post we will examine whether this is good advice with a simple multi-agent simulation, so read on!
Continue reading “How to be Successful! The Role of Risk-taking: A Simulation Study”
R Coding Challenge: How many Lockers are Open?

The German news magazine DER SPIEGEL has a regular puzzle section in its online version, called “Rätsel der Woche” (“Riddle of the Week”). Some of those puzzles are quite interesting but I am often too lazy to solve them analytically.
So I often kill two birds with one stone: having fun solving the puzzle with R and creating some new teaching material for my R classes! This is what we will do with one of those more interesting riddles, which is quite hard to solve analytically but relatively easy to solve with R, so read on!
Continue reading “R Coding Challenge: How many Lockers are Open?”